鲜花
听 Mea 讲树论,但是还是脱不了修锅的命运(
注:本文中,dfs 序 等同于 dfn 序。
树的基础
树的直径
定义就是树上的最长路径,非常好理解。
求法
对于所有树,均可以使用树形 DP 的方式求解,但是带负权的树据 Mea 说非常抽象,不怎么考,所以没什么用(
记录最长路和次长路即可。
参考代码(现场写的):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| int d1[N],d2[N],len;
void dfs(int now,int fa){
d1[now]=d2[now]=0;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa)continue;
dfs(E[i].to,now);
int temp=d1[E[i].to]+E[i].v;
if(d1[now]<temp){
d2[now]=d1[now];
d1[now]=temp;
}
else if(d2[now]<temp){
d2[now]=temp;
}
}
len=max(len,d1[now]+d2[now]);
return;
}
|
两次 dfs 即可。
这时,我们需要证明,树上任意一点与树上其他点形成的最长路径的终点是直径一个的端点。
设 a→y 是当前遍历到的最长路径,s→t 为直径,设 y 不为直径端点,钦定 disa→s≤disa→t。
- y 在 s→t 上,此时 disa→t<disa→y,则有 diss→y>diss→t,矛盾。
- a→y 与 s→t 有交 c→d,显然仍有 disa→t<disa→y,那么去掉相同部分可得 disc→y>disc→t,就转化成了第一种情况。
- a→y 与 s→t 无交,显然还是有 disa→t<disa→y,易发现 y 一定为叶子节点,故 a 比 y 离 s→t 近。所以一定有 diss→a→y>diss→a→t≥diss→t,矛盾。
证毕。
那就好实现了,直接 dfs 求两次距离当前点最远的点即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| int dep[N],ed;
void dfs(int now,int fa){
if(dep[now]>dep[ed])ed=now;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa)continue;
dep[E[i].to]=dep[now]+E[i].v;
dfs(E[i].to,now);
}
return;
}
...
dep[1]=0;dfs(1,0);
int st=ed;
dep[ed]=0;dfs(ed,0);
int len=dep[ed];
...
|
在这种情况下,是可以发现所有直径的中点重合。
证明很简单。设直径 s1→t1 的中点为 a1,s2→t2 的直径同。那么如果这两条直径中点不重合,一定能找到一条 s1→a1→a2→t2 或与其类似的路径。而 disa1→a2>0,故矛盾。
一些题
上面已经讲清楚了,略。
此处只讲 O(n) 做法。
考虑偏心距性质,如果该路径不完全重合于直径,那么可以分割为一条完全重合于直径的路径和几条完全不重合于直径的路径。令该路径为 a→k→b(k 在 s→t 上),那么有 disk→t>disb→farthestb,故如果该路径完全重合于直径一定不劣。
那么可以每次尺取一条完全重合于直径的路径,用一种类似于滑动窗口算法的方式枚举,然后统计直径两端偏心距的答案。
但是最大值不一定能在直径两端取到,就比如说长度的限制就等于直径的长度的时候。那么我们可以发现,每种情况的答案都至少统计了旁边子树的答案。由于直径的长度相对最长,所以这些未被选中路径的子树的答案最多也不会超过该处直径到某一端点的长度。所以这部分要取最大,以免错过正确答案。
由树的直径而来—树的中心
顾名思义,树的中心就是树的最中间的点,它被定义为离树的直径的中点最靠近的点,可以有多个。
求法与直径类似,就是还需要再遍历一边直径来求中心。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| ...
void dfs(int now,int f){
fa[now]=...;
...
}
...
...
fa[ed]=0;dfs(ed,0);
int dest=ed,nowtot=0,_1,_2,mid;
for(int i=dest;i;i=E[fa[i]].to){
nowtot+=E[fa[i]].v;
if(nowtot>dep[ed]/2){
_1=i;
_2=E[fa[i]].to;
if(nowtot-dep[ed]/2>=dep[ed]/2+E[fa[i]].v-nowtot)mid=_1;
else mid=_2;
break;
}
}
...
|
(上面的代码应该是对的吧,不知道,没测过)
又是一些题
感觉比上面的那个紫题还难。
考虑当 k=1 的时候,为了平均,必然选到树的中心。
当 k>1 时,首先,仍然要选树的中心。然后仍然为了平均,就以中心为根,贪心选择当前距离最远的叶子最远的那个路径,即 maxdep[now]−dep[now] 最大。排序选第 k+1 大即可,因为这个数最大的存的就是一条链上最多的节点数。
1
2
3
| sort(dd+1,dd+n+1,greater<int>());
dd[n+1]=0;
cout<<dd[k+1]+1;
|
没写 O(n2) 的算法,但是看起来好写多了。
- 算法一:时间复杂度 O(n2)
考虑枚举断边 (u,v),这个时候已经是 O(n) 的了,于是考虑在分离的两个连通块里选择哪两个点连接起来更优。由于此时要保证两连通块里的距离保持平均从而距离最短,那么选择这两个联通块里的中心一定不劣。
每次暴力求中心即可。
- 算法二:时间复杂度 O(nL) (L=Θ(n),L≤n)
考虑优化。
考虑断边可能存在的位置。如果断边不在直径上,那么有一连通块内必然存在原树的直径的长,和原树的答案一样,则一定不优。所以断边在直径上一定不劣。
所以每次在直径上枚举断边,暴力跑中心即可。
虽然直径的长度 L 与 n 同阶,但是速度还是显著的比算法一快。
继续优化。
考虑在枚举断边的时候,是重复 dfs 了很多东西的。由 树上任意一点为起点的最长路径的终点一定是直径的端点 可知,只需在直径两端点各进行一次 dfs 即可求解。
发现其实每次的答案的贡献来自于两连通块的直径或两连通块的半径和加上原边边权,统计一下即可。
剩下的最后一个问题是定中心的问题,其实很好解决。考虑有顺序地断直径上的边,必定有一个连通块的直径单调递减,另一个单调递增。那么维护中心就很简单了,按单调性在直径上跳即可。
算法三好难写啊 qwq,就写算法二吧。
然后我的半径求法跑得居然比树形 dp 快,但是容易写错。
感觉无论是代码实现还是理解都很简单,但是不知道为什么没几个人做。
考虑 k=0 时,因为树上每个点到另一个点的路径均只有一条路径,不能形成任何欧拉回路,所以每条边都需要走两次,ans=2×(n−1)。
那么 k=1 时,为了答案最优,我们就要连出最大的一条欧拉回路,由于树的形态,这条回路只能是一个环。那么显然,最大的环出自于连接直径的两端点,此时记直径长度为 L1,可以简单推得 ans=2×(n−1)−L1+1=2×n−L1−1。
k=2 时,容易想到用缩点的办法把刚刚的环缩成一个点再跑一次直径,但是如果这两条路径有重叠部分那就不好玩了。所以可以使用类似于网络流中退流的办法,把相交的两个路径转换为不交的两个路径,即把刚刚的直径的边权置为 −1,然后再跑一遍直径即可。注意此处只能用树形 dp 求解,因为有负边权的边。
此时 ans=2×n−L1−L2。
时间复杂度 O(n)。
树的重心
定义
对于无根树,对于所有点为根的情况,拥有最小的点最多的子树的根称为该树的重心。
有点抽象?
看看 Mea 的 pdf 吧:

性质
当且仅当以重心为根时,所有子树的大小不超过整棵树的一半。
怎么证?
首先,如果重心的某棵子树大小超过了整棵树的一半,那么如果重心向那棵子树转移一定不劣。
相似地,如果重心的某棵子树大小没有超过整棵树的一半,那么重心向那棵子树转移一定不优。
所以最优的情况下,重心的所有子树大小都没有超过整棵树的一半,此时重心往哪里转移都是不优的。
证毕。
一些题
模板,但是这道题点也带权。
原题是求一个点使得所有人到这个点的距离和最小。
考虑这个点的性质。假设这个点为重心,那么可以发现无论往哪个方向,变化量是非负的,因为 当且仅当以重心为根时,所有子树的大小不超过整棵树的一半。
所以重心的第二条性质出来了:树上所有的点到某个点的距离和当且仅当这个点取到重心时最小,如果有多个重心,那么取这些重心的距离和相等。
因此这道题就是求树的带权重心。
好像有两种算法求重心。
不知道是不是适用于求带权重心时。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| int w[N],siz[N],maxw[N],zx[2];
void dfs(int now,int fa){
siz[now]=w[now];
maxw[now]=0;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa)continue;
dfs(E[i].to,now);
siz[now]+=siz[E[i].to];
maxw[now]=max(maxw[now],siz[E[i].to]);
}
maxw[now]=max(maxw[now],sum-siz[now]);
if(maxw[now]<=sum/2){
zx[zx[0]!=0]=now;
}
return;
}
|
- 算法二:换根 dp 求树上所有点到某个点的距离和最小的点。
考虑先预处理出一个点到其他点的距离和,记 fu 是距离和,sizeu 是之前算出来了的子树大小,然后推出换根 dp 式子:
fv=fu+(n−sizev)×disu→v−sizev×disu→v=fu+(n−sizev×2)×disu→v
不要以为只用判断 n−sizev×2 的正负性就能转移了,disu→v 的值不一样还是白搭,还是要算出所有点的 f 值再做比较找找最大的那个点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| int f[N],dep[N],w[N],siz[N],res,zx;
void dfs(int now,int fa){
siz[now]=w[now];
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa)continue;
dep[E[i].to]=dep[now]+E[i].v;
dfs(E[i].to,now);
siz[now]+=siz[E[i].to];
}
f[1]+=dep[now]*w[now];
return;
}
void dfs2(int now,int fa){
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa)continue;
f[E[i].to]=f[now]+(sum-siz[E[i].to]*2)*E[i].v;
dfs2(E[i].to,now);
}
if(f[now]<res){
res=f[now];
zx=now;
}
return;
}
|
考虑只有一个重心时,随便选定一条边,删了之后然后再加回来就行了。
有两个重心时,考虑这两个重心的相对位置:
这里引用一下某洛谷大佬的图:

如果有两个重心 1 和 2,则这两个重心必然直接相连,否则往这两个重心中间的点转移一定不劣。
根据重心的性质,假如说 2 号重心为根时的最大子树为 5 号或者 6 号子树,那么 1 号为根时最大子树一定大于 2 号的最大子树,矛盾,所以 2 号重心的最大子树是 1 号节点为根的子树,1 号节点同理。
所以我们可以推出 3 号子树与 4 号子树的大小和等于 5 号子树与 6 号子树的大小和。
怎么破坏这种平衡?
那就是随便选一个 3 号子树或者 4 号子树的叶子连到 2 号节点即可。
鲜花:我当时把这个当成了 CF780C,然后…
首先猜结论:以树的重心为根然后染色一定最优。
但是后面发现,好像在哪里染都是一样的。/jk
为什么 OI Wiki 上要用这个做例题啊…/fn
好好好,为了练习还是写一遍树的重心吧…
…???看错题号了???
好好好,不写重心了,直接一遍 DFS!
考虑什么样的点改造之后有可能成为重心。题中提示重心子树大小不超过 2n,那么这种点要么是原来就是重心,要么就是有且仅有一个子树的子树分离之后原子树和分离后的子树大小不大于 2n。
由于是我最不擅长的 dp,所以只能看题解。
然而看了题解还是不会,看来得要补补 dp 了,先鸽。
悲报
Mea 讲的重心的题一个也不会做。
遍历序与 LCA
直接抛题了。
P2680 运输计划
树上差分的题。
写完这道题就写树上差分的笔记。
考虑求最大值最小,想到二分答案,这样把求解变成了判定。
每次树上差分(边差分)出链长大于当前二分答案的链长的重叠部分,再在这些重叠部分处查找有没有一条边的边权大于最长链与该二分答案出的链的长度差即可。
显然,求链长需要预处理出 LCA ,不预处理 LCA 时间复杂度为 O(nlog2n),应该能勉强卡过。
好好好,注意常数!理论时间复杂度 O(nlogn)。
然后注意用 unordered_map 会喜提 95pts。
树上差分
树上差分就是将信息转化成差分的形式记录,最后进行一遍前缀和得到原数组。
有两种基本形式:边差分与点差分。
边差分:fu 与 fv 加上 v,然后 flca(u,v) 减去 2×v。
点差分:fu 与 fv 加上 v,然后 flca(u,v) 减去 v,ffa(lca(u,v)) 减去 v。
P3398 仓鼠找 sugar
考虑两条路径相交时的性质。
此时,其中一条路径的起点和终点的 LCA,必定在另一条路径上。
如何判断点是否在路径上?
一种简单的方法是:利用路径长判断。如果判断 k 是否在路径 a→b 上,只需判断 disa→k+disk→b=disa→b。
怪不得只有绿,但是我没看出来怎么做。/kk
注意要要判断两次,即 a,b 的 LCA 判断是否在 c→d 上,c,d 的 LCA 同,任意一个满足即可。
P1600 天天爱跑步

(好恐怖)
喜报,作者有些看不懂,所以这应该是最后一道专属 LCA 板块的题了。
喜报,作者看了一个下午,才有点起色…
终于看懂了,之前是我傻逼了。
考虑将一段路径转化成两段,一段向上走,一段向下走,用符号语言理解:
s→t⇒s→son(LCAs,t)+LCAs,t→t
那么就可以分两段处理了。
首先,对于每一个点 s 都有观察时的时间 ws,因为在上面我们已经将一条路径分成了只上升与只下降两部分,那么我们就可以只维护两个桶:对于向上走,维护当前点被多少路径覆盖;和对于向下走,维护终点深度减去当前链长度的桶(也就是把链拉直了)。
这道题感觉不是差分,就是一个桶维护加生存周期标记。所以不要看代码没有差分的部分就看不懂了。
统计答案时,统计桶的增量即可;记录标记 −1 时,记得要记录到当前路径端点的父亲,否则会少统计一个。
注意在 −1,+1 操作时顺序要与 dfs 与统计答案的顺序一样。
写完之后感觉不看看就又会理解错…/kk
终于完结一个版块了!!!
树链剖分
分为重链剖分,长链剖分,和实链剖分(不写,填 LCT 的坑的时候写在 LCT 那里)。
重链剖分

浅浅一眼,作用很多。
一些基础定义
定义重子节点为一个节点子树最大的儿子,其余儿子为轻子节点。
定义重边为父亲连向自己的重子节点的边,其余父亲向儿子连的边叫轻边。
定义几条重边首尾衔接起来的一条链为重链。(出生登场)
显然,如果把单个节点也看成一条重链的话,整个树会被剖分成很多条重链。
OI Wiki 上放了图,那我也放一张:
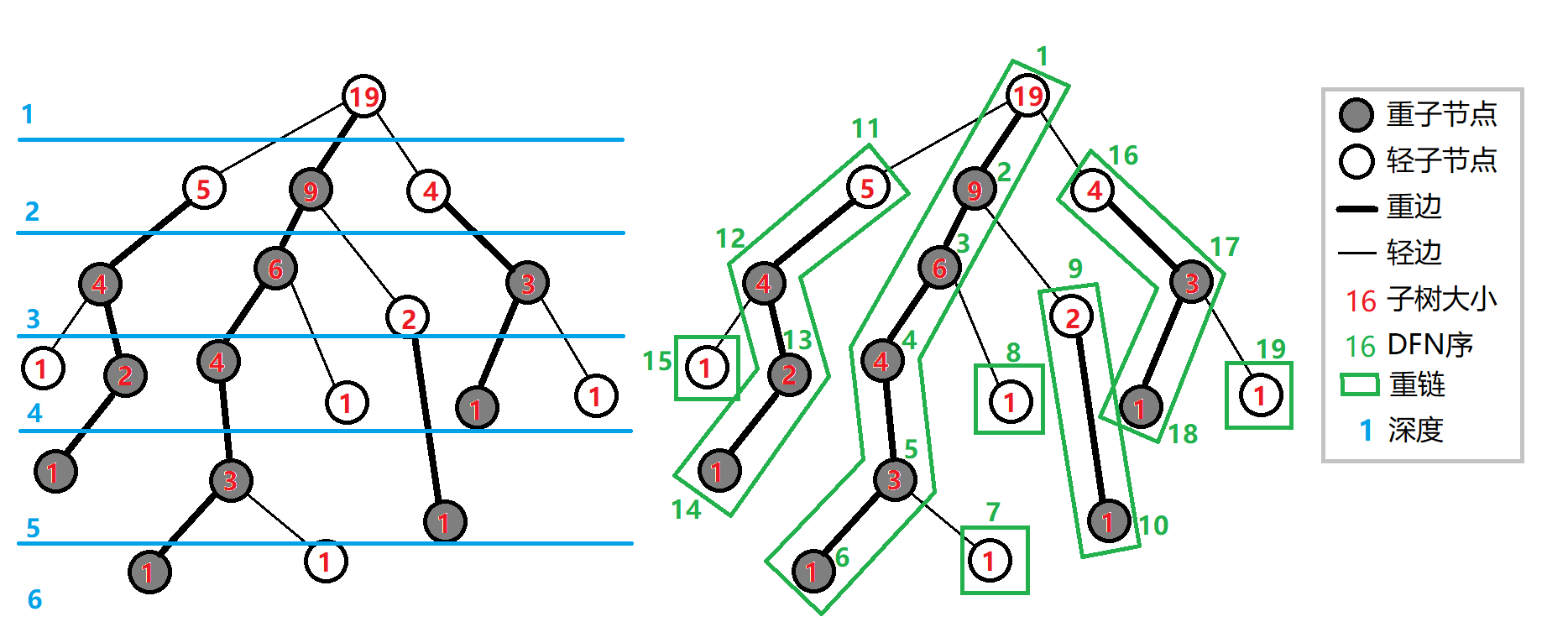
(一样的图)
实现
两次 dfs 即可。
第一次预处理出重子节点,深度,子树大小和父节点。
第二次求 dfs 序(dfn 数组),每个节点的链顶,和 dfs 序对应的节点(rk 数组)。
如果 dfn[2]=3,代表 2 号节点第 3 次被访问到。
而 rk[3]=2,代表第 3 次访问到的节点为 2 号节点。
实现代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| int dep[N],siz[N],fa[N],hs[N];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[hs[now]]<siz[E[i].to])hs[now]=E[i].to;
}
return;
}
int rk[N],dfn[N],dfncnt,ltop[N];
void dfs2(int now,int top){
dfn[now]=++dfncnt;
rk[dfncnt]=now;
ltop[now]=top;
if(!hs[now])return;
dfs2(hs[now],top);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hs[now])continue;
dfs2(E[i].to,E[i].to);
}
return;
}
|
由于是现写的代码,也一样地不知道代码是否正确,但是应该是对的?
即时UPD:经测试,有误,不过已经改回来了,并且加了注释提醒自己。
性质
最本质的一条:树上任意节点都只会被一条重链覆盖。
由于剖分时是按照重边优先遍历来遍历的,所以 dfn 序也很特殊,按照重链的剖分顺序并且每个重链内部从上到下遍历,会发现这个顺序和 dfn 序是一致的。(可能没讲太清楚…)
还有一条:由于剖分时重子节点的子树大小最大,所以每向下走一条轻边时,子树大小至少减半。
所以这条性质证明了树剖求 LCA 的复杂度:如果把一条路径拆成起点与终点的 LCA 向下走走到起点和终点两条路径,那么根据这两条性质,因为 LCA 的子树大小与 n 同阶,所以最多经过 O(logn) 条重链,复杂度就有保证了。
常见应用
多用于维护信息和平均比倍增快地求 LCA。
(想在写板子题之前找点hack数据,没找到,太失败了)
用于求 LCA
自认为是下面维护路径信息的基础。
每次根据重链的顶端大小情况跳重链即可。上面也已经有证明,时间复杂度 O(logn)。
易错点已在代码中标出。
1
2
3
4
5
6
7
8
|
int LCA(int u,int v){
while(ltop[u]!=ltop[v]){
if(dep[ltop[u]]>dep[ltop[v]])u=fa[ltop[u]];
else v=fa[ltop[v]];
}
return ((dep[u]>dep[v])?v:u);
}
|
为什么是 dep[ltop[u]]>dep[ltop[v]] 呢?考虑这是跳重链,所以要比较重链的顶端。
用于维护路径信息(P2590)
这部分应该最后会贴一个完整代码。
维护路径信息指的是如维护路径点权最大值,点权和,修改点权等等。
显然,树剖强悍的 O(logn) 求 LCA 和一条重链上 dfn 序连续的性质让树剖可以在 O(log2n) 的时间内解决一个询问。
考虑这样一个问题:
n 个节点的树,q 次询问,询问内容:
- 求 u→v 路径上点权最大值。
- 求 u→v 路径上点权和。
- 修改点 u 的点权为 v。
(其实这里是可以考路径修改的,这个时候的线段树就要有标记这种东西了(悲))
依据一条重链上 dfn 序连续的性质,我们可以对所有节点按 dfn 序建一棵线段树,而不是对每一条重链建一棵线段树(不然不好控制空间大小)。
首先树剖后,注意建树的过程(rk 数组终于用上了):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
int segtm[1000001],segts[1000001];
void pushup(int now){
segtm[now]=max(segtm[now<<1],segtm[now<<1|1]);
segts[now]=segts[now<<1]+segts[now<<1|1];
return;
}
void bulid(int now,int l,int r){
if(l==r){
segtm[now]=w[rk[l]];
segts[now]=w[rk[l]];
return;
}
int mid=(l+r)>>1;
bulid(now<<1,l,mid);
bulid(now<<1|1,mid+1,r);
pushup(now);
return;
}
|
然后询问区间最大值,询问区间和等正常敲线段树板子即可。
现在重头戏来了:融合求 LCA 和线段树询问来完成路径上的询问。
注意到线段树是按照 dfn 序建的,所以对于每一个求 LCA 时跳到的重链,都可以直接用线段树直接区间询问该重链上形成贡献的部分。
那么代码就和求 LCA 时的代码差不多了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
int qmax(int u,int v){
int nowmax=-1e9;
while(ltop[u]!=ltop[v]){
if(dep[ltop[u]]>dep[ltop[v]]){
nowmax=max(nowmax,getmax(1,1,n,dfn[ltop[u]],dfn[u]));
u=fa[ltop[u]];
}
else{
nowmax=max(nowmax,getmax(1,1,n,dfn[ltop[v]],dfn[v]));
v=fa[ltop[v]];
}
}
if(dep[u]>dep[v])swap(u,v);
nowmax=max(nowmax,getmax(1,1,n,dfn[u],dfn[v]));
return nowmax;
}
|
其他询问或修改同。
贴个完整代码,把重剖学完就要鸽一鸽树论了,咕咕。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
| #include<bits/stdc++.h>
using namespace std;
struct line{
int to,link;
}E[200002];
int segtm[1000010],segts[1000010],head[100001],tot=1;
void addE(int u,int v){
E[++tot].link=head[u];
E[tot].to=v;
head[u]=tot;
return;
}
int dep[100001],siz[100001],hs[100001],fa[100001];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[hs[now]]<siz[E[i].to])hs[now]=E[i].to;
}
return;
}
int dfn[100001],rk[100001],dfncnt,ltop[100001];
void dfs2(int now,int top){
ltop[now]=top;
dfn[now]=++dfncnt;
rk[dfncnt]=now;
if(!hs[now])return;
dfs2(hs[now],top);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hs[now])continue;
dfs2(E[i].to,E[i].to);
}
return;
}
int w[100001],n,m;
void pushup(int now){
segtm[now]=max(segtm[now<<1],segtm[now<<1|1]);
segts[now]=segts[now<<1]+segts[now<<1|1];
return;
}
void bulid(int now,int l,int r){
if(l==r){
segtm[now]=w[rk[l]];
segts[now]=w[rk[l]];
return;
}
int mid=(l+r)>>1;
bulid(now<<1,l,mid);
bulid(now<<1|1,mid+1,r);
pushup(now);
return;
}
void upd(int now,int l,int r,int q,int v){
if(l==r){
segtm[now]=v;
segts[now]=v;
return;
}
int mid=(l+r)>>1;
if(q>mid)upd(now<<1|1,mid+1,r,q,v);
else upd(now<<1,l,mid,q,v);
pushup(now);
return;
}
int getmax(int now,int l,int r,int sl,int sr){
int res=-1e9;
if(l==sl&&r==sr)return segtm[now];
int mid=(l+r)>>1;
if(sl<=mid)res=max(res,getmax(now<<1,l,mid,sl,min(sr,mid)));
if(sr>mid)res=max(res,getmax(now<<1|1,mid+1,r,max(sl,mid+1),sr));
return res;
}
int getsum(int now,int l,int r,int sl,int sr){
int res=0;
if(sl==l&&r==sr)return segts[now];
int mid=(l+r)>>1;
if(sl<=mid)res+=getsum(now<<1,l,mid,sl,min(mid,sr));
if(sr>mid)res+=getsum(now<<1|1,mid+1,r,max(sl,mid+1),sr);
return res;
}
int qsum(int u,int v){
int nowsum=0;
while(ltop[u]!=ltop[v]){
if(dep[ltop[u]]>dep[ltop[v]]){
nowsum+=getsum(1,1,n,dfn[ltop[u]],dfn[u]);
u=fa[ltop[u]];
}
else{
nowsum+=getsum(1,1,n,dfn[ltop[v]],dfn[v]);
v=fa[ltop[v]];
}
}
if(dep[u]<dep[v])swap(u,v);
nowsum+=getsum(1,1,n,dfn[v],dfn[u]);
return nowsum;
}
int qmax(int u,int v){
int nowmax=-1e9;
while(ltop[u]!=ltop[v]){
if(dep[ltop[u]]>dep[ltop[v]]){
nowmax=max(nowmax,getmax(1,1,n,dfn[ltop[u]],dfn[u]));
u=fa[ltop[u]];
}
else{
nowmax=max(nowmax,getmax(1,1,n,dfn[ltop[v]],dfn[v]));
v=fa[ltop[v]];
}
}
if(dep[u]<dep[v])swap(u,v);
nowmax=max(nowmax,getmax(1,1,n,dfn[v],dfn[u]));
return nowmax;
}
int main(){
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin>>n;
int x,y;
for(int i=1;i<n;i++){
cin>>x>>y;
addE(x,y);
addE(y,x);
}
for(int i=1;i<=n;i++)cin>>w[i];
dfs1(1,0);
dfs2(1,1);
bulid(1,1,n);
string s;
int T;
cin>>T;
while(T--){
s="";
cin>>s>>x>>y;
if(s[1]=='M')cout<<qmax(x,y)<<"\n";
else if(s[1]=='S')cout<<qsum(x,y)<<"\n";
else upd(1,1,n,dfn[x],y);
}
return 0;
}
|
用于维护子树信息(P3384)
由于这道题与上道题的询问更多样,并且这道题线段树我写挂了 2 次,所以还是把这道题的完整代码贴上来。
考虑如何维护子树信息。因为 dfs 求 dfn 序的时候,仍然满足进入一棵子树后,遍历完该子树的所有节点才会回溯出来,所以一棵子树内的 dfn 序连续。
那么这就好维护了,OI Wiki 里面写的甚至还要维护一个什么 bottom 数组,实际上这个 dfn 序是与子树大小有关的,直接用 siz 数组转化为区间询问即可。
1
2
3
4
5
6
7
8
|
void updsubt(int u,int w){
upd(1,1,n,dfn[u],dfn[u]+siz[u]-1,w);
return;
}
int qsumsubt(int u){
return getsum(1,1,n,dfn[u],dfn[u]+siz[u]-1);
}
|
注意右边界的取值即可。
完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
| #include<bits/stdc++.h>
using namespace std;
#define int long long
struct line{
int to,link;
}E[200003];
int head[100001],tot=1;
void addE(int u,int v){
E[++tot].link=head[u];
head[u]=tot;
E[tot].to=v;
return;
}
int siz[100001],dep[100001],hson[100001],fa[100001];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
return;
}
int dfn[100001],rk[100001],ltop[100001],dfncnt;
void dfs2(int now,int top){
dfn[now]=++dfncnt;
rk[dfncnt]=now;
ltop[now]=top;
if(!hson[now])return;
dfs2(hson[now],top);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dfs2(E[i].to,E[i].to);
}
return;
}
int segts[400001],lazy[400001],w[100001];
void pushdown(int now,int l,int r){
int mid=(l+r)/2;
segts[now<<1]+=(mid-l+1)*lazy[now];
segts[now<<1|1]+=(r-mid)*lazy[now];
lazy[now<<1]+=lazy[now];
lazy[now<<1|1]+=lazy[now];
lazy[now]=0;
return;
}
void pushup(int now){
segts[now]=segts[now<<1]+segts[now<<1|1];
return;
}
void upd(int now,int l,int r,int sl,int sr,int v){
if(l==sl&&r==sr){
segts[now]+=v*(r-l+1);
lazy[now]+=v;
return;
}
pushdown(now,l,r);
int mid=(l+r)/2;
if(sl<=mid)upd(now<<1,l,mid,sl,min(mid,sr),v);
if(sr>mid)upd(now<<1|1,mid+1,r,max(sl,mid+1),sr,v);
pushup(now);
return;
}
int getsum(int now,int l,int r,int sl,int sr){
if(l==sl&&r==sr)return segts[now];
pushdown(now,l,r);
int mid=(l+r)/2,res=0;
if(sl<=mid)res+=getsum(now<<1,l,mid,sl,min(sr,mid));
if(sr>mid)res+=getsum(now<<1|1,mid+1,r,max(sl,mid+1),sr);
pushup(now);
return res;
}
void bulid(int now,int l,int r){
if(l==r){
segts[now]=w[rk[l]];
return;
}
int mid=(l+r)/2;
bulid(now<<1,l,mid);
bulid(now<<1|1,mid+1,r);
pushup(now);
return;
}
int n,m,s,p;
void updsubt(int u,int w){
upd(1,1,n,dfn[u],dfn[u]+siz[u]-1,w);
return;
}
int qsumsubt(int u){
return getsum(1,1,n,dfn[u],dfn[u]+siz[u]-1);
}
int qsuml(int u,int v){
int nowsum=0;
while(ltop[u]!=ltop[v]){
if(dep[ltop[u]]>dep[ltop[v]]){
nowsum+=getsum(1,1,n,dfn[ltop[u]],dfn[u]);
u=fa[ltop[u]];
}
else{
nowsum+=getsum(1,1,n,dfn[ltop[v]],dfn[v]);
v=fa[ltop[v]];
}
}
if(dep[u]>dep[v])swap(u,v);
nowsum+=getsum(1,1,n,dfn[u],dfn[v]);
return nowsum;
}
void updl(int u,int v,int w){
while(ltop[u]!=ltop[v]){
if(dep[ltop[u]]>dep[ltop[v]]){
upd(1,1,n,dfn[ltop[u]],dfn[u],w);
u=fa[ltop[u]];
}
else{
upd(1,1,n,dfn[ltop[v]],dfn[v],w);
v=fa[ltop[v]];
}
}
if(dep[u]>dep[v])swap(u,v);
upd(1,1,n,dfn[u],dfn[v],w);
return;
}
signed main(){
cin>>n>>m>>s>>p;
for(int i=1;i<=n;i++)cin>>w[i];
int x,y;
for(int i=1;i<n;i++){
cin>>x>>y;
addE(x,y);
addE(y,x);
}
dfs1(s,0);
dfs2(s,s);
bulid(1,1,n);
int op,z;
while(m--){
cin>>op>>x;
if(op==1){
cin>>y>>z;
updl(x,y,z);
}
else if(op==2){
cin>>y;
cout<<qsuml(x,y)%p<<"\n";
}
else if(op==3){
cin>>y;
updsubt(x,y);
}
else cout<<qsumsubt(x)%p<<"\n";
}
return 0;
}
|
一些非传统应用
还有一道题就下班了,咕咕。
有些时候,重剖除了这些应用以外,还有一些不常见的应用。
由于作者只想写洛谷上的题,所以就有了:CF1174F。
其他题欢迎在评论区补充。
交互-CF1174F
还好的一道题,但是记得 cout.flush()!
题目主要是想让你用 2 种询问来确定一个点。
首先要确定这个点的深度,那么在 1 号节点问路径距离即可。
考虑重链剖分每次跳一次轻边子树至少减半的性质,使用跳重链的方式保证能在 36 次以内完成确定(36≤2×logmaxn)。
那么如何跳重链呢?
考虑求路径长的公式:disu→v=disu→LCA(u,v)+disLCA(u,v)→v=depu+depv−2×depLCA(u,v),可以发现如果我们能确定一个点到所求点的路径长,那么就一定能求出它们的 LCA 深度,再用类似于 k 级祖先的方式求出它们的 LCA 之后就可以继续询问下一个轻子节点了。注意这里不排除它们的 LCA 就是我们要求的点,所以要特判。
但是有了重链剖分,对于这道题谁会用树上 k 级祖先这种东西啊。
考虑既然我们的目的是找到所求节点在这条重链上的哪个轻子节点的子树中,那么在剖分时记录重链长度,第一次直接询问重链最底部与所求点的路径长以求 LCA,再在 LCA 处询问路径 LCA→x 上的下一个点即可。
迭代最多 logn 次即可求出该点。
放代码,下班!QwQ
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
| #include<bits/stdc++.h>
using namespace std;
struct line{
int to,link;
}E[400004];
int head[200001],tot;
void addE(int u,int v){
E[++tot].to=v;
E[tot].link=head[u];
head[u]=tot;
return;
}
int siz[200001],dep[200001],fa[200001],hson[200001];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
return;
}
int dfn[200001],rk[200001],dfncnt,ltop[200001],lsiz[200001];
void dfs2(int now,int top){
dfn[now]=++dfncnt;
rk[dfncnt]=now;
ltop[now]=top;
lsiz[top]++;
if(!hson[now])return;
dfs2(hson[now],top);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dfs2(E[i].to,E[i].to);
}
return;
}
int main(){
ios::sync_with_stdio(0);
int n;
cin>>n;
int x,y;
for(int i=1;i<n;i++){
cin>>x>>y;
addE(x,y);
addE(y,x);
}
dfs1(1,0);
dfs2(1,1);
int no=1;
cout<<"d "<<1<<endl;
cout.flush();
int depx;
cin>>depx;
while(1){
cout<<"d "<<rk[dfn[no]+lsiz[no]-1]<<"\n";
cout.flush();
int depno;
cin>>depno;
if(depno==0){
cout<<"! "<<rk[dfn[no]+lsiz[no]-1];
cout.flush();
return 0;
}
int deplca=(dep[rk[dfn[no]+lsiz[no]-1]]-depno+depx)/2;
no=rk[dfn[no]+lsiz[no]-1-dep[rk[dfn[no]+lsiz[no]-1]]+deplca];
if(dep[no]==depx){
cout<<"! "<<no<<"\n";
cout.flush();
return 0;
}
cout<<"s "<<no<<"\n";
cout.flush();
cin>>no;
if(dep[no]==depx){
cout<<"! "<<no<<"\n";
cout.flush();
return 0;
}
}
}
|
树上启发式合并
鸽…咕咕咕…
然后作者回来了。
树上启发式合并的思想很精妙,感觉和人类智慧乱搞算法有的一拼。
考虑随便抛出一棵树,假设我们要数树上每个点子树的颜色:

先不管颜色是什么,考虑如何优化 O(n2) 的暴力统计。
由于每次我们都要逐一求颜色个数并清空桶,我们可以利用继承的思想来优化,也就是把该节点花时间最多的儿子向上继承显然最优,也就有了 小的往大的合并 这种俗语了。
就像上面的树,重边已用 H 标识标记。可以发现如果
对于 2 号节点,显然 从 7 号节点继承比从 6 号节点继承优。
这样做的复杂度是 O(nlogn) 的,可以感性理解一下,因为每次暴力算轻儿子,子树大小至少减半,对于所有轻儿子都是这样,所以是 O(nlogn)。
典题。
首先使用树剖的 dfn 序。然后每次像启发式合并一样统计。
维护出现次数的桶,并且对每个出现次数维护和,当要删除贡献时,直接清零,注意清零的卡常即可。
(不然要被链卡到 O(n2))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
#include<bits/stdc++.h>
using namespace std;
int n,c[100001];
vector<int> tag[100001];
vector<int>::iterator it;
int cnt[100001];
long long ans[100001];
struct line{
int to,link;
}E[200001];
int head[100001],tot;
void addE(int u,int v){
E[++tot].link=head[u];
head[u]=tot;
E[tot].to=v;
return;
}
int dep[100001],hson[100001],fa[100001],siz[100001];
long long sum[100001];
int L[100001],R[100001],rk[100001],dfncnt;
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
L[now]=++dfncnt;
rk[dfncnt]=now;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
R[now]=dfncnt;
return;
}
int maxx;
void add(int id){
int u=rk[id];
cnt[c[u]]++;
tag[cnt[c[u]]].push_back(c[u]);
sum[cnt[c[u]]]+=c[u];
maxx=max(cnt[c[u]],maxx);
return;
}
void init(int id){
int si=tag[1].size();
for(int i=0;i<si;i++)cnt[tag[1][i]]=0;
for(int i=1;i<=maxx;i++)tag[i].clear(),sum[i]=0;
maxx=0;
return;
}
void dfs(int now,bool fl=0){
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dfs(E[i].to);
}
if(hson[now])dfs(hson[now],1);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
for(int k=L[E[i].to];k<=R[E[i].to];k++)add(k);
}
add(L[now]);
ans[now]=sum[maxx];
if(!fl)init(now);
return;
}
int main(){
ios::sync_with_stdio(0);
cin>>n;
for(int i=1;i<=n;i++)cin>>c[i];
int x,y;
for(int i=1;i<n;i++)cin>>x>>y,addE(x,y),addE(y,x);
dfs1(1,0);
dfs(1,1);
for(int i=1;i<=n;i++)cout<<ans[i]<<" ";
return 0;
}
|
省流:别用什么 set<int> a,b; a=b; 之类的赋值,会 T 飞!!!!用 swap !!!
直接暴力维护取值集合。使用树上差分,设 disu=w1⊕⋯⊕wu(路径异或和),那么 disu→v=disu⊕disv⊕wLCA(u,v)。
如果有 disu→v=0,显然 disu=disv⊕wLCA(u,v),用 set 或者 unordered_set 维护取值集合即可。如果有重复的,直接将该集合清空,然后答案加一。显然这样做是最优的,因为可以取 LCA(u,v) 来赋值,可以赋一个什么 2114514+u 这种点权使异或和一定不为 0,那么赋值后可以使子树内完全符合条件,还可以防止子树内的点和子树外的点的路径形成不合法的情况。
注意 unordered_set 的空间和省流即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| #include<bits/stdc++.h>
using namespace std;
int n,m;
struct line{
int to,link;
}E[400001];
int head[200001],tot;
void addE(int u,int v){
E[++tot].link=head[u];
head[u]=tot;
E[tot].to=v;
return;
}
set<int> s[200001];
set<int>::iterator it;
int ans;
int dep[200001],siz[200001],w[200001],dis[200001],fa[200001];
int hson[200001];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
dis[now]^=w[now];
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dis[E[i].to]^=dis[now];
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
return;
}
void dfs(int now,int dep=0){
if(!hson[now]){
s[now].insert(dis[now]);
return;
}
int maxx=0;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now])continue;
dfs(E[i].to,dep+1);
if(s[E[i].to].size()>s[maxx].size())maxx=E[i].to;
}
swap(s[now],s[maxx]);
if(s[now].find(dis[now]^w[now])!=s[now].end()){
s[now].clear();
ans++;
return;
}
s[now].insert(dis[now]);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==maxx)continue;
for(it=s[E[i].to].begin();it!=s[E[i].to].end();it++){
if(s[now].find(*it^w[now])!=s[now].end()){
s[now].clear();
ans++;
return;
}
}
for(it=s[E[i].to].begin();it!=s[E[i].to].end();it++)s[now].insert(*it);
s[E[i].to].clear();
}
if(dep>n)exit(0);
return;
}
int main(){
ios::sync_with_stdio(0);
cin>>n;
for(int i=1;i<=n;i++)cin>>w[i];
int x,y;
for(int i=1;i<n;i++){
cin>>x>>y;
addE(x,y);
addE(y,x);
}
dfs1(1,0);
dfs(1);
cout<<ans;
return 0;
}
|
好像 O(set.find())<O(set.count()),好神奇。
还有 2 题的启发式合并,先去写什么计划了。
Mea 的 pdf 已经讲得比较清楚了。
先正常 dsu 一遍,对每个深度维护一个桶,然后计数即可。对于在该点的询问,就直接访问该桶即可。
感觉这次 unordered_set 是可行的。开写!
做这道题脑子是昏的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
#include<bits/stdc++.h>
using namespace std;
int n;
unordered_map<string,int> mp;
int mpcnt;
struct line{
int to,link;
}E[200001];
int head[100001],tot;
void addE(int u,int v){
E[++tot].link=head[u];
E[tot].to=v;
head[u]=tot;
return;
}
int dep[100001],siz[100001],hson[100001],fa[100001];
int cnt[200001],w[100001],L[100001],R[100001],rk[200001],dfncnt;
vector<pair<int,int> > Q[100001];
int ans[100001];
unordered_set<int> s[200001];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
L[now]=++dfncnt;
rk[dfncnt]=now;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
R[now]=dfncnt;
return;
}
void add(int id){
int u=rk[id];
if(!s[dep[u]].count(w[u])){
s[dep[u]].insert(w[u]);
cnt[dep[u]]++;
}
return;
}
void dsu(int now,bool fl=0){
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dsu(E[i].to);
}
if(hson[now])dsu(hson[now],1);
add(L[now]);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
for(int j=L[E[i].to];j<=R[E[i].to];j++)add(j);
}
for(auto num:Q[now]){
ans[num.second]=cnt[dep[now]+num.first];
}
if(fl)return;
for(int i=dep[now];i<=dep[now]+siz[now]-1;i++)cnt[i]=0,s[i].clear();
return;
}
int deg[100001];
int main(){
ios::sync_with_stdio(0);
int m;
cin>>n;
string s;
int ff;
for(int i=1;i<=n;i++){
cin>>s>>ff;
if(ff)addE(ff,i),deg[i]++;
if(!mp[s])mp[s]=++mpcnt;
w[i]=mp[s];
}
cin>>m;
int v,k;
for(int i=1;i<=m;i++){
cin>>v>>k;
Q[v].push_back(make_pair(k,i));
}
for(int k=1;k<=n;k++)if(deg[k]==0)dfs1(k,0),dsu(k);
for(int i=1;i<=m;i++)cout<<ans[i]<<"\n";
return 0;
}
|
例题:CF741D
树启发明者出的题。
考虑一个 重排之后能形成回文字符串 的路径的性质,不难发现它的各个字母出现次数最多有一个是奇数,想到异或。
记 du 为从根到该点路径的异或和,那么对这 22 个字符进行状压,只有 23 种情况符合条件:000⋯0,000⋯1,⋯,100⋯0。
那么对于每个点记录该点子树的 d,不难发现其实 du→v=du⊕dv,那么可以用桶记录每个 d 深度的最大值进行 dsu,然后 O(23) 判断合法即可。注意每个节点还要像它的儿子的答案去取最大值。最后对于每个点去找 depu+depv 的最大值,然后减去 2×depnow 即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
#include<bits/stdc++.h>
using namespace std;
int n;
int get(char a){
return 1<<(a-'a');
}
int ri[24];
void init(){
for(int i=0;i<=21;i++)ri[i+1]=1<<i;
return;
}
struct line{
int to,link,w;
}E[1000001];
int head[500001],w[500001],tot;
void addE(int u,int v,char c){
E[++tot].w=get(c);
E[tot].to=v;
E[tot].link=head[u];
head[u]=tot;
return;
}
int dis[10000001];
int L[500001],R[500001],rk[500001],dep[500001],siz[500001];
int hson[500001],fa[500001],di[500001],dfncnt;
void dfs(int now,int f){
fa[now]=f;
siz[now]=1;
L[now]=++dfncnt;
rk[dfncnt]=now;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
w[E[i].to]=E[i].w;
di[E[i].to]=di[now]^E[i].w;
dfs(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
R[now]=dfncnt;
return;
}
int ans[500001];
void dsu(int now,bool fl){
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dsu(E[i].to,0);
}
if(hson[now])dsu(hson[now],1);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
for(int j=L[E[i].to];j<=R[E[i].to];j++){
for(int l=0;l<=22;l++)ans[now]=max(dis[di[rk[j]]^ri[l]]+dep[rk[j]],ans[now]);
}
for(int j=L[E[i].to];j<=R[E[i].to];j++)dis[di[rk[j]]]=max(dis[di[rk[j]]],dep[rk[j]]);
}
for(int l=0;l<=22;l++)ans[now]=max(dis[di[now]^ri[l]]+dep[now],ans[now]);
dis[di[now]]=max(dis[di[now]],dep[now]);
ans[now]-=2*dep[now];
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now])continue;
ans[now]=max(ans[now],ans[E[i].to]);
}
if(fl)return;
for(int i=L[now];i<=R[now];i++)dis[di[rk[i]]]=-1e9;
return;
}
int main(){
ios::sync_with_stdio(0);
cin.tie(0),cout.tie(0);
for(int i=1;i<=(1<<22);i++)dis[i]=-1e9;
init();
cin>>n;
char cc;
int x;
for(int i=2;i<=n;i++){
cin>>x>>cc;
addE(x,i,cc);
}
dfs(1,0);
dsu(1,1);
for(int i=1;i<=n;i++)cout<<max(ans[i],0)<<" ";
return 0;
}
|
长链剖分
就是把 重儿子 的定义改为 高度最高的儿子。
长链剖分优化 dp
例题:CF1009F
没看太懂,dsu 不就行了?
写个长剖下实现的 dsu 算了。
感觉挺简单的,直接贴代码吧。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
#include<bits/stdc++.h>
using namespace std;
int n;
struct line{
int to,link;
}E[2000001];
int head[1000001],tot;
void addE(int u,int v){
E[++tot].to=v;
E[tot].link=head[u];
head[u]=tot;
return;
}
int cnt[1000001],xb,maxdep;
int dep[1000001],dd[1000001],hson[1000001],fa[1000001],ans[1000001];
int L[1000001],R[1000001],rk[1000001],dfncnt;
void dfs(int now,int f){
fa[now]=f;
L[now]=++dfncnt;
rk[dfncnt]=now;
maxdep=max(maxdep,dep[now]);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs(E[i].to,now);
dd[now]=max(dd[now],dd[E[i].to]+1);
if(dd[E[i].to]>dd[hson[now]])hson[now]=E[i].to;
}
R[now]=dfncnt;
return;
}
void upd(int num){
if(cnt[num]>cnt[xb]||(cnt[num]==cnt[xb]&&xb>num))xb=num;
return;
}
void dsu(int now,bool fl=0){
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dsu(E[i].to);
}
if(hson[now])dsu(hson[now],1);
cnt[dep[now]]++;upd(dep[now]);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
for(int j=L[E[i].to];j<=R[E[i].to];j++)cnt[dep[rk[j]]]++,upd(dep[rk[j]]);
}
ans[now]=xb-dep[now];
if(fl)return;
for(int i=dep[now];i<=maxdep;i++)cnt[i]=0;
xb=0;
return;
}
int main(){
ios::sync_with_stdio(0);
cin>>n;
int x,y;
for(int i=1;i<n;i++)cin>>x>>y,addE(x,y),addE(y,x);
dfs(1,0);
dsu(1,1);
for(int i=1;i<=n;i++)cout<<ans[i]<<"\n";
return 0;
}
|
好像长链 dsu 比重链 dsu 慢(复杂度假了)?离谱,这个优化 dp 还是没有理解。
好像长链剖分优化 dp 是要记录 dp 时所有节点的状态的,草。
然后下一道题就是正宗优化了,然而由于作者 dp 能力 欠佳,可能需要较久时间看懂如何推的 dp 转移式。
看懂了。
正宗例题:P5904
这道题看你怎么用 dsu。只能用 dp。
设 fi,j 为在 i 子树中距离 i 距离为 j 的点个数,gi,j 为在 i 子树中,满足 disx→LCA(x,y)=disy→LCA(x,y)=disi→LCA(x,y)+j 的 (x,y) 无序对数量。
不难发现一下较为简单的转移:
fi,j←∑fson(i),j−1gi,j←∑gson(i),j+1
gi,j 的转移还有一种情况,就是 x,y 在不同儿子的子树中,那么有:
g_{i,j}\leftarrow\sum_{x,y\in son(i)\and x\not=y}f_{x,j-1}\times f_{y,j-1}
然后就是对 ans 的贡献了。对于每个点,首先, ans←gnow,0。
然后讨论其他能对 ans 做出贡献的地方,即 (x,y) 和 z 在 i 的不同子树上,可知:
ans\leftarrow\sum_j\sum_{x,y\in son(i)\and x\not=y}g_{x,j+1}\times f_{y,j-1}
那么…这是一个 O(n2) 算法,因为我们开不了二维数组…
因为深度为下标,并且可以通过指针直接 O(1) 转移,考虑使用长链剖分优化,时间复杂度优化至 O(n)。
有几点需要注意的:
- 注意数组下标 ∈[0,heightnow),不能越界。
- 注意叶子节点的高度为 1,因为 fnow,0 对于所有节点都有。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
#include<bits/stdc++.h>
using namespace std;
int n;
const int N=1e5+5;
struct line{
int to,link;
}E[N<<1];
int head[N],tot;
void addE(int u,int v){
E[++tot].link=head[u];
E[tot].to=v;
head[u]=tot;
return;
}
long long dep[N],qsy[N<<2],dd[N],fa[N],hson[N];
void dfs(int now,int f){
fa[now]=f;
dd[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs(E[i].to,now);
dd[now]=max(dd[now],dd[E[i].to]+1);
if(dd[E[i].to]>dd[hson[now]])hson[now]=E[i].to;
}
return;
}
long long ans=0;
long long *no=qsy,*f[N],*g[N];
void dp(int now){
if(hson[now])f[hson[now]]=f[now]+1,g[hson[now]]=g[now]-1,dp(hson[now]);
f[now][0]=1;
ans+=g[now][0];
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
f[E[i].to]=no,no+=dd[E[i].to]<<1;
g[E[i].to]=no,no+=dd[E[i].to]<<1;
dp(E[i].to);
for(int j=0;j<dd[E[i].to];j++){
if(j)ans+=f[now][j-1]*g[E[i].to][j];
ans+=f[E[i].to][j]*g[now][j+1];
}
for(int j=0;j<dd[E[i].to];j++){
g[now][j+1]+=f[E[i].to][j]*f[now][j+1],f[now][j+1]+=f[E[i].to][j];
if(j)g[now][j-1]+=g[E[i].to][j];
}
}
return;
}
int main(){
ios::sync_with_stdio(0);
cin>>n;
int x,y;
for(int i=1;i<n;i++)cin>>x>>y,addE(x,y),addE(y,x);
dfs(1,0);
f[1]=no,no+=dd[1]<<1;
g[1]=no,no+=dd[1]<<1;
dp(1);
cout<<ans;
return 0;
}
|
长链剖分求树上 k 级祖先
设 2i≤k<2i+1,那么可以先向上跳到 2i 级祖先,然后使用长链剖分。
可以证明 lchain≥k−2i,分两种情况。
- 跳完之后跳到了同一条链上,显然,lchain≥2i>k−2i。
- 跳完之后跳到了不同链上,则必有 lorginal_chain<lnow_chain,因为该链并没有向原来的节点延伸,则有 lnow_chain≥2i,剩余同上。
那么可以在链顶暴力记录 1∼l 级祖先与儿子即可。
空间 O(n)。时间复杂度 O(nlogn+q)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
|
#include<bits/stdc++.h>
using namespace std;
int n,q;
struct line{
int to,link;
}E[1000001];
int head[500001],tot;
void addE(int u,int v){
E[++tot].link=head[u];
E[tot].to=v;
head[u]=tot;
return;
}
int fa[500001][29];
vector<int> up[500001];
int ltop[500001],dfn[500001],rk[500001],dfncnt;
long long ans;
int dep[500001],dd[500001],hson[500001];
void dfs(int now,int f){
fa[now][0]=f;
for(int i=0;fa[now][i];)i++,fa[now][i]=fa[fa[now][i-1]][i-1];
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs(E[i].to,now);
dd[now]=max(dd[now],dd[E[i].to]+1);
if(dd[E[i].to]>dd[hson[now]])hson[now]=E[i].to;
}
return;
}
void init(int now,int top){
dfn[now]=++dfncnt;
rk[dfncnt]=now;
ltop[now]=top;
if(!hson[now])return;
if(now==top){
for(int i=1,o=fa[now][0];o&&i<=dd[now];i++,o=fa[o][0])up[now].push_back(o);
}
init(hson[now],top);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now][0]||E[i].to==hson[now])continue;
init(E[i].to,E[i].to);
}
return;
}
#define ui unsigned int
ui s;
int lg[500001]={-1};
inline ui get(ui x) {
x ^= x << 13;
x ^= x >> 17;
x ^= x << 5;
return s = x;
}
int ask(int u,int k){
if(k==0)return u;
u=fa[u][lg[k]];
k-=(1<<lg[k]);
if(k<=dep[u]-dep[ltop[u]])return rk[dfn[u]-k];
return up[ltop[u]][k+dep[ltop[u]]-dep[u]-1];
}
int lans;
signed main(){
ios::sync_with_stdio(0);
cin>>n>>q>>s;
int sss=q,kkk;
int kl;
for(int i=1;i<=n;i++){
cin>>kl;
if(kl)addE(kl,i);
else kkk=i;
lg[i]=lg[i>>1]+1;
}
dfs(kkk,0);
init(kkk,kkk);
while(q--){
ui v=(get(s)^lans)%n+1,k=(get(s)^lans)%(dep[v]+1);
lans=ask(v,k);
ans=ans^(1ll*(sss-q)*lans);
}
cout<<ans;
return 0;
}
|
调了好久,结果跑不过树剖跳重链,输!
一些练手题
下面是整理的一些例题与变式。还有树分治,虚树,树同构三个板块。
例题:P4211
小清新题,求 ∑i=lrdepLCA(i,z)。
初次拿到这道题肯定毫无思路。考虑将 depu 转化为 dis1→u,发现这道题可以使用差分。具体就是对于 1→i 路径上的所有边权值加 1,因为 LCA 一定在 1→i 这条路径上。最后统计 1→z 路径的边权和即可。
但是这样差分的复杂度是 O(nq) 的。尝试优化。
考虑离线,对状态进行前缀和优化,即算出 [1,i](i∈[1,n]) 的所有状态。对于每个询问,求 ans[1,r]−ans[1,l) 即可。用树链剖分 + 线段树维护链加一。时间复杂度 O(nlog2n)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
|
#include<bits/stdc++.h>
using namespace std;
int n;
#define int long long
const int mod=201314;
struct line{
int to,link;
}E[100001];
int head[50001],tot;
void addE(int u,int v){
E[++tot].link=head[u];
E[tot].to=v;
head[u]=tot;
return;
}
int fa[100001],dep[100001],hson[100001],siz[100001];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
return;
}
int dfn[100001],rk[100001],dfncnt,ltop[100001];
void dfs2(int now,int top){
dfn[now]=++dfncnt;
rk[dfncnt]=now;
ltop[now]=top;
if(!hson[now])return;
dfs2(hson[now],top);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dfs2(E[i].to,E[i].to);
}
return;
}
unordered_map<int,int> Q[50001];
vector<int> G[50001];
vector<int>::iterator it;
int xds[800001],lazy[800001];
void pushdown(int now,int l,int r){
if(lazy[now]){
int mid=(l+r)/2;
xds[now<<1]+=(mid-l+1)*lazy[now];
xds[now<<1]%=mod;
xds[now<<1|1]+=(r-mid)*lazy[now];
xds[now<<1|1]%=mod;
lazy[now<<1]+=lazy[now];
lazy[now<<1]%=mod;
lazy[now<<1|1]+=lazy[now];
lazy[now<<1|1]%=mod;
lazy[now]=0;
}
return;
}
void pushup(int now){
xds[now]=(xds[now<<1]+xds[now<<1|1])%mod;
return;
}
void upd(int now,int l,int r,int sl,int sr,int v){
if(l==sl&&r==sr){
xds[now]+=(r-l+1)*v;
lazy[now]+=v;
return;
}
int mid=(l+r)/2;
pushdown(now,l,r);
if(sl<=mid)upd(now<<1,l,mid,sl,min(sr,mid),v);
if(sr>mid)upd(now<<1|1,mid+1,r,max(sl,mid+1),sr,v);
pushup(now);
return;
}
int getsum(int now,int l,int r,int sl,int sr){
if(l==sl&&r==sr)return xds[now];
int mid=(l+r)/2,res=0;
pushdown(now,l,r);
if(sl<=mid)res+=getsum(now<<1,l,mid,sl,min(sr,mid)),res%=mod;
if(sr>mid)res+=getsum(now<<1|1,mid+1,r,max(sl,mid+1),sr),res%=mod;
pushup(now);
return res;
}
void mdf(int u){
while(u){
upd(1,1,n,dfn[ltop[u]],dfn[u],1);
u=fa[ltop[u]];
}
return;
}
int qsum(int u){
int res=0;
while(u)res+=getsum(1,1,n,dfn[ltop[u]],dfn[u]),u=fa[ltop[u]],res%=mod;
return res;
}
int l[50001],r[50001],z[50001];
signed main(){
ios::sync_with_stdio(0);
int q;
cin>>n>>q;
int temp;
for(int i=2;i<=n;i++)cin>>temp,addE(temp+1,i);
dfs1(1,0);
dfs2(1,1);
for(int i=1;i<=q;i++)cin>>l[i]>>r[i]>>z[i],G[l[i]].push_back(z[i]+1),G[r[i]+1].push_back(z[i]+1);
for(int i=1;i<=n;i++){
mdf(i);
for(it=G[i].begin();it!=G[i].end();it++)if(Q[i][*it]==0)Q[i][*it]=qsum(*it);
}
for(int i=1;i<=q;i++){
cout<<(Q[r[i]+1][z[i]+1]-Q[l[i]][z[i]+1]+mod)%mod<<"\n";
}
return 0;
}
|
线段树又写挂 2 次,悲。
例题:P5305
这道题是上一道题的扩展版。
不难想到继续离线做,但是需要用线段树支持区间加 1k−0k,2k−1k⋯(d+1)k−dk 的操作。
考虑标记这段区间被标记覆盖了多少次,预处理出 dk 的值,然后每次下放标记的时候,就加上 lazy×(deprkrk−(deprkl−1)k) 即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
|
#include<bits/stdc++.h>
using namespace std;
const int mod=998244353;
#define int long long
int sum(int a,int b){
a+=b;
a%=mod;
return a;
}
int minu(int a,int b){
a-=b%mod;
a=(a+mod)%mod;
return a;
}
int _k[50001],n,m,k;
int ksm(int a,int b){
if(b==0)return 1;
if(b==1)return a;
return (b&1?a:1)*(ksm(a*a%mod,b/2))%mod;
}
struct line{
int to,link;
}E[100001];
int head[50001],tot;
void addE(int u,int v){
E[++tot].link=head[u];
head[u]=tot;
E[tot].to=v;
return;
}
int fa[50001],dep[50001],siz[50001],hson[50001];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
return;
}
int dfn[50001],rk[50001],ltop[50001],dfncnt;
void dfs2(int now,int top){
ltop[now]=top;
dfn[now]=++dfncnt;
rk[dfncnt]=now;
if(!hson[now])return;
dfs2(hson[now],top);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dfs2(E[i].to,E[i].to);
}
return;
}
int xds[400001];
int lazy[400001];
void pushdown(int now,int l,int r){
if(lazy[now]){
int mid=(l+r)/2;
lazy[now<<1]+=lazy[now];
lazy[now<<1|1]+=lazy[now];
xds[now<<1]+=minu(_k[dep[rk[mid]]],_k[dep[rk[l]]-1])*lazy[now]%mod;
xds[now<<1]%=mod;
xds[now<<1|1]+=minu(_k[dep[rk[r]]],_k[dep[rk[mid]]])*lazy[now]%mod;
xds[now<<1|1]%=mod;
lazy[now]=0;
}
return;
}
void pushup(int now){
xds[now]=sum(xds[now<<1],xds[now<<1|1]);
return;
}
void upd(int now,int l,int r,int sl,int sr){
if(l==sl&&r==sr){
lazy[now]++;
xds[now]+=minu(_k[dep[rk[r]]],_k[dep[rk[l]]-1])%mod;
xds[now]%=mod;
return;
}
pushdown(now,l,r);
int mid=(l+r)/2;
if(sl<=mid)upd(now<<1,l,mid,sl,min(sr,mid));
if(sr>mid)upd(now<<1|1,mid+1,r,max(sl,mid+1),sr);
pushup(now);
return;
}
int getsum(int now,int l,int r,int sl,int sr){
if(l==sl&&r==sr)return xds[now];
pushdown(now,l,r);
int mid=(l+r)/2,res=0;
if(sl<=mid)res=sum(res,getsum(now<<1,l,mid,sl,min(sr,mid)));
if(sr>mid)res=sum(res,getsum(now<<1|1,mid+1,r,max(sl,mid+1),sr));
pushup(now);
return res;
}
void mdf(int u){
while(u)upd(1,1,n,dfn[ltop[u]],dfn[u]),u=fa[ltop[u]];
return;
}
int qsum(int u){
int res=0;
while(u)res=sum(res,getsum(1,1,n,dfn[ltop[u]],dfn[u])),u=fa[ltop[u]];
return res;
}
vector<pair<int,int> > Q[50001];
int ans[50001];
signed main(){
ios::sync_with_stdio(0);
cin>>n>>m>>k;
_k[1]=1;
for(int i=2;i<=n;i++)_k[i]=ksm(i,k);
dep[1]=1;
int x,y;
for(int i=2;i<=n;i++)cin>>x,addE(x,i);
for(int i=1;i<=m;i++){
cin>>x>>y;
Q[x].push_back(make_pair(i,y));
}
dfs1(1,0);
dfs2(1,1);
for(int i=1;i<=n;i++){
mdf(i);
int si=Q[i].size();
for(int j=0;j<si;j++)ans[Q[i][j].first]=qsum(Q[i][j].second);
}
for(int i=1;i<=m;i++)cout<<ans[i]<<"\n";
return 0;
}
|
例题:P2146
不难看出 install u 操作是修改所有 1→u 路径上的节点状态为已安装,而 uninstall u 操作是修改以 u 为根的子树的所有节点的状态为未安装。我们需要一种数据结构维护这些,并且需要输出每次修改了多少个。
线段树就够了。维护已安装状态出现的次数即可。设定三个懒标记:
- lazy=0,无需操作。
- lazy=1,将当前区间内的所有节点设定为已安装。
- lazy=2,将当前区间内的所有节点设定为未安装。
下放懒标记时分类讨论,然后在修改时统计修改后的值与原来的值的差的绝对值即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
|
#include<bits/stdc++.h>
using namespace std;
int n,q;
struct line{
int to,link;
}E[200005];
int head[100005],tot;
void addE(int u,int v){
E[++tot].link=head[u];
E[tot].to=v;
head[u]=tot;
return;
}
int dep[100001],siz[100001],hson[100001],fa[100001];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
return;
}
int dfn[100001],rk[100001],dfncnt,ltop[100001];
void dfs2(int now,int top){
ltop[now]=top;
dfn[now]=++dfncnt;
rk[dfncnt]=now;
if(!hson[now])return;
dfs2(hson[now],top);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dfs2(E[i].to,E[i].to);
}
return;
}
int xds[400001];
int lazy[400001];
void pushup(int now){
xds[now]=xds[now<<1]+xds[now<<1|1];
return;
}
void pushdown(int now,int l,int r){
if(!lazy[now])return;
int mid=(l+r)/2;
if(lazy[now]==1){
lazy[now<<1]=lazy[now<<1|1]=1;
xds[now<<1]=mid-l+1;
xds[now<<1|1]=r-mid;
lazy[now]=0;
return;
}
lazy[now<<1]=lazy[now<<1|1]=2;
xds[now<<1]=0;
xds[now<<1|1]=0;
lazy[now]=0;
return;
}
int upd(int now,int l,int r,int sl,int sr,bool ty){
if(l==sl&&r==sr){
int org=xds[now];
if(ty==1)lazy[now]=1,xds[now]=r-l+1;
else lazy[now]=2,xds[now]=0;
return abs(org-xds[now]);
}
pushdown(now,l,r);
int mid=(l+r)/2,res=0;
if(sl<=mid)res+=upd(now<<1,l,mid,sl,min(sr,mid),ty);
if(sr>mid)res+=upd(now<<1|1,mid+1,r,max(sl,mid+1),sr,ty);
pushup(now);
return res;
}
int mdf(int u){
int res=0;
while(u)res+=upd(1,1,n,dfn[ltop[u]],dfn[u],1),u=fa[ltop[u]];
return res;
}
int main(){
ios::sync_with_stdio(0);
cin>>n;
int x;
string s;
for(int i=2;i<=n;i++)cin>>x,addE(x+1,i);
cin>>q;
dfs1(1,0);
dfs2(1,1);
for(int i=1;i<=q;i++){
cin>>s>>x;
x++;
if(s[0]=='i')cout<<mdf(x)<<"\n";
else cout<<upd(1,1,n,dfn[x],dfn[x]+siz[x]-1,0)<<"\n";
}
return 0;
}
|
线段树记得开 4 倍空间!!!!
例题(?):P3258
树上差分例题。
细节较多,但是题意是真的读不懂。
小猫第一次要到达 a1,所以显然先要在 a1 处拿一块糖果。
然后出发时的房间都不用拿糖果,于是要对 a1∼an 去重。
然后就是普通点差分即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
#include<bits/stdc++.h>
using namespace std;
int n;
struct line{
int to,link;
}E[600001];
int head[300001],tot;
void addE(int u,int v){
E[++tot].link=head[u];
head[u]=tot;
E[tot].to=v;
return;
}
int w[100001];
int fa[300001][26],dep[300001];
void dfs(int now,int f){
fa[now][0]=f;
for(int i=0;fa[now][i];)i++,fa[now][i]=fa[fa[now][i-1]][i-1];
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
dfs(E[i].to,now);
}
return;
}
int LCA(int u,int v){
if(dep[u]>dep[v])swap(u,v);
for(int i=dep[v]-dep[u],ci=0;i;i>>=1,ci++)if(i&1)v=fa[v][ci];
if(u==v)return u;
for(int i=23;i>=0;i--)if(fa[u][i]!=fa[v][i])u=fa[u][i],v=fa[v][i];
return fa[u][0];
}
int ans[300001];
void calc(int now){
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now][0])continue;
calc(E[i].to);
ans[now]+=ans[E[i].to];
}
return;
}
int Q[300001];
int main(){
ios::sync_with_stdio(0);
cin>>n;
for(int i=1;i<=n;i++)cin>>Q[i];
int x,y;
for(int i=1;i<n;i++)cin>>x>>y,addE(x,y),addE(y,x);
dfs(1,0);
for(int i=1;i<n;i++){
int lca=LCA(Q[i],Q[i+1]);
ans[Q[i]]++,ans[Q[i+1]]++,ans[lca]--,ans[fa[lca][0]]--;
}
calc(1);
for(int i=1;i<=n;i++)ans[Q[i]]--;
ans[Q[1]]++;
for(int i=1;i<=n;i++)cout<<ans[i]<<"\n";
return 0;
}
|
例题:P4315
树剖 + 线段树的综合题,很适合练手。
我这道题线段树写挂了,然后调了 2h。
没什么可说的,注意路径 LCA 不要查询或修改,然后注意标记下放即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
|
#include<bits/stdc++.h>
using namespace std;
int n;
string s;
int x,y,z;
struct line{
int to,link,w;
}E[200001];
int head[100001],tot;
void addE(int u,int v,int w){
E[++tot].link=head[u];
E[tot].to=v;
E[tot].w=w;
head[u]=tot;
return;
}
int dw[100001];
int dep[100001],fa[100001],siz[100001],hson[100001],w[100001];
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+1;
w[E[i].to]=E[i].w;
dw[(i+1)/2]=E[i].to;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
return;
}
int dfn[100001],rk[100001],dfncnt,ltop[100001];
void dfs2(int now,int top){
ltop[now]=top;
dfn[now]=++dfncnt;
rk[dfncnt]=now;
if(!hson[now])return;
dfs2(hson[now],top);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dfs2(E[i].to,E[i].to);
}
return;
}
int xds[400001],sumtag[400001],covtag[400001];
void pushup(int now){
xds[now]=max(xds[now<<1],xds[now<<1|1]);
return;
}
void bulid(int now,int l,int r){
if(l==r){
xds[now]=w[rk[l]];
return;
}
int mid=(l+r)/2;
bulid(now<<1,l,mid);
bulid(now<<1|1,mid+1,r);
pushup(now);
return;
}
void pushdown(int now,int l,int r){
assert(!(covtag[now]&&sumtag[now]));
if(covtag[now]){
covtag[now]--;
sumtag[now<<1]=0;
sumtag[now<<1|1]=0;
xds[now<<1]=covtag[now];
xds[now<<1|1]=covtag[now];
covtag[now<<1]=covtag[now]+1;
covtag[now<<1|1]=covtag[now]+1;
covtag[now]=0;
return;
}
if(sumtag[now]){
if(covtag[now<<1])covtag[now<<1]+=sumtag[now],xds[now<<1]=covtag[now<<1]-1;
else sumtag[now<<1]+=sumtag[now],xds[now<<1]+=sumtag[now];
if(covtag[now<<1|1])covtag[now<<1|1]+=sumtag[now],xds[now<<1|1]=covtag[now<<1|1]-1;
else sumtag[now<<1|1]+=sumtag[now],xds[now<<1|1]+=sumtag[now];
sumtag[now]=0;
}
return;
}
void cov(int now,int l,int r,int sl,int sr,int v){
if(l==sl&&r==sr){
covtag[now]=v+1;
sumtag[now]=0;
xds[now]=v;
return;
}
pushdown(now,l,r);
int mid=(l+r)/2;
if(sl<=mid)cov(now<<1,l,mid,sl,min(sr,mid),v);
if(sr>mid)cov(now<<1|1,mid+1,r,max(sl,mid+1),sr,v);
pushup(now);
return;
}
void add(int now,int l,int r,int sl,int sr,int v){
if(l==sl&&r==sr){
if(covtag[now])covtag[now]+=v;
else sumtag[now]+=v;
xds[now]+=v;
return;
}
pushdown(now,l,r);
int mid=(l+r)/2;
if(sl<=mid)add(now<<1,l,mid,sl,min(mid,sr),v);
if(sr>mid)add(now<<1|1,mid+1,r,max(sl,mid+1),sr,v);
pushup(now);
return;
}
int getmax(int now,int l,int r,int sl,int sr){
if(l==sl&&r==sr)return xds[now];
pushdown(now,l,r);
int mid=(l+r)/2,res=0;
if(sl<=mid)res=max(res,getmax(now<<1,l,mid,sl,min(sr,mid)));
if(sr>mid)res=max(res,getmax(now<<1|1,mid+1,r,max(sl,mid+1),sr));
pushup(now);
return res;
}
void uadd(int u,int v,int w){
while(ltop[u]!=ltop[v]){
if(dep[ltop[u]]>dep[ltop[v]])add(1,1,n,dfn[ltop[u]],dfn[u],w),u=fa[ltop[u]];
else add(1,1,n,dfn[ltop[v]],dfn[v],w),v=fa[ltop[v]];
}
if(u!=v){
if(dfn[u]>dfn[v])swap(u,v);
add(1,1,n,dfn[u]+1,dfn[v],w);
}
return;
}
void ucover(int u,int v,int w){
while(ltop[u]!=ltop[v]){
if(dep[ltop[u]]>dep[ltop[v]])cov(1,1,n,dfn[ltop[u]],dfn[u],w),u=fa[ltop[u]];
else cov(1,1,n,dfn[ltop[v]],dfn[v],w),v=fa[ltop[v]];
}
if(u!=v){
if(dfn[u]>dfn[v])swap(u,v);
cov(1,1,n,dfn[u]+1,dfn[v],w);
}
return;
}
int qmax(int u,int v){
int res=0;
while(ltop[u]!=ltop[v]){
if(dep[ltop[u]]>dep[ltop[v]])res=max(res,getmax(1,1,n,dfn[ltop[u]],dfn[u])),u=fa[ltop[u]];
else res=max(res,getmax(1,1,n,dfn[ltop[v]],dfn[v])),v=fa[ltop[v]];
}
if(u!=v){
if(dfn[u]>dfn[v])swap(u,v);
res=max(res,getmax(1,1,n,dfn[u]+1,dfn[v]));
}
return res;
}
int main(){
ios::sync_with_stdio(0);
cin>>n;
for(int i=1;i<n;i++)cin>>x>>y>>z,addE(x,y,z),addE(y,x,z);
dfs1(1,0);
dfs2(1,0);
bulid(1,1,n);
int de=0;
while(1){
cin>>s;
de++;
if(s[0]=='S')break;
else if(s[0]=='M')cin>>x>>y,cout<<qmax(x,y)<<"\n";
else if(s[0]=='A')cin>>x>>y>>z,uadd(x,y,z);
else if(s[1]=='h')cin>>x>>y,cov(1,1,n,dfn[dw[x]],dfn[dw[x]],y);
else cin>>x>>y>>z,ucover(x,y,z);
}
return 0;
}
|
终于结束了,之后再补剩余的题(理论来讲还有 3 道)。
树分治
分为点分治,边分治,和点分树,边分树。
此处先只写点分治,其他的科技后面再补。
1
2
点分治
本来想写 3 道点分治的,结果这三道都可以用 dsu 做,那么,就先写两道,然后有一道用 dsu 和点分治都写一遍,另外一道就只用点分治写就行了。
小声 bb:虚树会鸽,所以写完这个和树哈希就跑路了。
点分治常用于处理大规模路径信息。
具体地,我们每次选取一个点,处理经过该点的所有路径的信息,然后删去该点,递归处理该点所有子树。假设共递归 h 层,时间复杂度 O(hn)。
显然,每块取重心分治最优,时间复杂度 O(nlogn)。
例题:P3806
提供两种 O(mnlogn) 做法。
- dsu
当我使用 dsu:无语死了,这是什么简单题。
不管输出格式一发就过了,40ms。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
#include<bits/stdc++.h>
using namespace std;
int n,m,x,y,z;
struct line{
int to,link,w;
}E[20001];
int head[10001],tot;
void addE(int u,int v,int w){
E[++tot].link=head[u];
E[tot].to=v;
head[u]=tot;
E[tot].w=w;
return;
}
int dep[10001],siz[10001],fa[10001],hson[10001];
int R[10001],L[10001],rk[10001],dfncnt;
void dfs1(int now,int f){
fa[now]=f;
siz[now]=1;
L[now]=++dfncnt;
rk[dfncnt]=now;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f)continue;
dep[E[i].to]=dep[now]+E[i].w;
dfs1(E[i].to,now);
siz[now]+=siz[E[i].to];
if(siz[E[i].to]>siz[hson[now]])hson[now]=E[i].to;
}
R[now]=dfncnt;
return;
}
int Q[101];
bool ans[101];
unordered_set<int> s;
void dsu(int now,bool fl=0){
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
dsu(E[i].to);
}
if(hson[now])dsu(hson[now],1);
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||E[i].to==hson[now])continue;
for(int j=L[E[i].to];j<=R[E[i].to];j++){
for(int k=1;k<=m;k++){
if(s.count(Q[k]+2*dep[now]-dep[rk[j]]))ans[k]=1;
}
}
for(int j=L[E[i].to];j<=R[E[i].to];j++)s.insert(dep[rk[j]]);
}
for(int k=1;k<=m;k++){
if(s.count(dep[now]+Q[k]))ans[k]=1;
}
s.insert(dep[now]);
if(fl)return;
s.clear();
return;
}
int main(){
ios::sync_with_stdio(0);
cin>>n>>m;
int x,y,z;
for(int i=1;i<n;i++)cin>>x>>y>>z,addE(x,y,z),addE(y,x,z);
for(int i=1;i<=m;i++)cin>>Q[i];
dfs1(1,0);
dsu(1,1);
for(int i=1;i<=m;i++)cout<<(ans[i]?"AYE\n":"NAY\n");
return 0;
}
|
由于可以开 104 个 unordered_set,这道题应该还可以继续优化,但是作者太懒了。
- 点分治
重心写挂了,然后虚空调试 1.5h,草!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
#include<bits/stdc++.h>
using namespace std;
int n,m;
struct line{
int to,link,w;
}E[20001];
int head[10001],tot;
void addE(int u,int v,int w){
E[++tot].w=w;
E[tot].to=v;
E[tot].link=head[u];
head[u]=tot;
return;
}
int Q[101],ans[101];
int dep[10001],dis[10001],dp[10001]={1000000000},fa[10001];
int vis[10001],sum,siz[10001];
int rt;
void dfs(int now,int f){
fa[now]=f;
sum++;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==fa[now]||vis[E[i].to])continue;
dfs(E[i].to,now);
}
return;
}
int L[10001],R[10001],rk[10001],dfncnt;
void _dfs(int now,int f){
L[now]=++dfncnt;
rk[dfncnt]=now;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f||vis[E[i].to])continue;
dep[E[i].to]=dep[now]+E[i].w;
_dfs(E[i].to,now);
}
R[now]=dfncnt;
return;
}
void _getrt(int now,int f){
siz[now]=1;
dp[now]=0;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f||vis[E[i].to])continue;
_getrt(E[i].to,now);
siz[now]+=siz[E[i].to];
dp[now]=max(siz[E[i].to],dp[now]);
}
dp[now]=max(dp[now],sum-siz[now]);
if(dp[now]<dp[rt])rt=now;
return;
}
void getrt(int now){
rt=dfncnt=0;
_getrt(now,0);
dep[rt]=0;
_dfs(rt,0);
return;
}
bool s[10000001];
int in[10000001],cn;
void solve(int now){
vis[now]=1;
s[0]=1;
cn=0;
for(int i=head[now];i;i=E[i].link){
if(vis[E[i].to])continue;
for(int j=L[E[i].to];j<=R[E[i].to];j++){
for(int k=1;k<=m;k++)if(Q[k]-dep[rk[j]]>=0&&Q[k]-dep[rk[j]]<=1e7&&s[Q[k]-dep[rk[j]]])ans[k]=1;
}
for(int j=L[E[i].to];j<=R[E[i].to];j++)if(dep[rk[j]]<=1e7&&!s[dep[rk[j]]])s[dep[rk[j]]]=1,in[++cn]=dep[rk[j]];
}
for(int i=1;i<=cn;i++)s[in[i]]=0;
for(int i=head[now];i;i=E[i].link){
if(vis[E[i].to])continue;
sum=siz[E[i].to];
getrt(E[i].to);
solve(rt);
}
}
int main(){
ios::sync_with_stdio(0);
cin>>n>>m;
int x,y,z;
for(int i=1;i<n;i++)cin>>x>>y>>z,addE(x,y,z),addE(y,x,z);
for(int i=1;i<=m;i++)cin>>Q[i];
dfs(1,0);
getrt(1),solve(rt);
for(int i=1;i<=m;i++)cout<<(ans[i]?"AYE\n":"NAY\n");
return 0;
}
|
例题:P4178
考虑这道题是求 [0,k] 的路径数量,那么我们不难发现这道题就是单点修改,区间前缀和查询,使用树状数组维护即可。
注意树状数组的上界是 k,不是 n。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
|
#include<bits/stdc++.h>
using namespace std;
int n,k;
struct line{
int to,link,w;
}E[800001];
int head[400001],tot;
void addE(int u,int v,int w){
E[++tot].w=w;
E[tot].to=v;
E[tot].link=head[u];
head[u]=tot;
return;
}
int dep[400001],vis[400001],siz[400001],dp[400001]={998244353},rt;
int sum,dfncnt,L[400001],R[400001];
int T[400002];
int lowbit(int x){
return x&-x;
}
int getsum(int x){
int res=0;
while(x>0){
res+=T[x];
x-=lowbit(x);
}
return res;
}
void upd(int x,int v){
while(x<=k){
T[x]+=v;
x+=lowbit(x);
}
return;
}
int rk[400001];
void dfs(int now,int f){
L[now]=++dfncnt;
rk[dfncnt]=now;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f||vis[E[i].to])continue;
dep[E[i].to]=dep[now]+E[i].w;
dfs(E[i].to,now);
}
R[now]=dfncnt;
return;
}
void _getrt(int now,int f){
dp[now]=0;
siz[now]=1;
for(int i=head[now];i;i=E[i].link){
if(E[i].to==f||vis[E[i].to])continue;
_getrt(E[i].to,now);
siz[now]+=siz[E[i].to];
dp[now]=max(siz[E[i].to],dp[now]);
}
dp[now]=max(dp[now],sum-siz[now]);
if(dp[now]<dp[rt])rt=now;
return;
}
void getrt(int now){
rt=dfncnt=0;
sum=siz[now];
_getrt(now,0);
dep[rt]=0;
dfs(rt,0);
return;
}
int ans=0;
void solve(int now){
vis[now]=1;
for(int i=head[now];i;i=E[i].link){
if(vis[E[i].to])continue;
for(int j=L[E[i].to];j<=R[E[i].to];j++)if(dep[rk[j]]<=k)ans+=getsum(k-dep[rk[j]])+1;
for(int j=L[E[i].to];j<=R[E[i].to];j++)if(dep[rk[j]]<=k)upd(dep[rk[j]],1);
}
for(int i=1;i<=k;i++)T[i]=0;
for(int i=head[now];i;i=E[i].link){
if(vis[E[i].to])continue;
getrt(E[i].to);
solve(rt);
}
}
int main(){
ios::sync_with_stdio(0);
cin>>n;
int x,y,z;
for(int i=1;i<n;i++)cin>>x>>y>>z,addE(x,y,z),addE(y,x,z);
cin>>k;
siz[1]=n;
getrt(1),solve(rt);
cout<<ans;
return 0;
}
|
还剩下两道题作为以后的练习题,直接进入树哈希。
树同构(树哈希)
顾名思义,就是检查两棵树的结构是否相同。
有 AHU 算法和树哈希两种比较方式,而树哈希更常用,于是就用树哈希来求解。
最常用的树哈希基于多重集的一个哈希函数。由于树点有子节点,那么哈希函数可以写成:
f(x)=(c+v∈son(x)∑g(f(v)))modm
其中 g 函数是一个映射,通常使用 xor shift:
1
2
3
4
5
6
7
8
| unsigned long long shift(unsigned long long x){
x^=mask;
x^=x<<13;
x^=x>>7;
x^=x<<17;
x^=mask;
return x;
}
|
当然可以选择不同的移位位数,但是 x^=mask 是防止树哈希被卡的关键一步。
看样子错误率较高?错误的。
有人证明了当哈希值域 m=O(nx)(x≥3) 时,它的错误率是 O(n1),甚至可以达到 O(poly(n)1) 的,但是看不懂,所以不搬了。
模板题:P5043 [BJOI2015]树的同构
对于无根树,我们要找一个关键点来进行树哈希。(或者使用换根 dp)
考虑树的重心只有两个,那么可以以重心为根进行哈希,如果重心有两个,就取较小的一个哈希值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
#include<bits/stdc++.h>
using namespace std;
int n[51],m;
struct line{
int to,link;
}E[101][51];
int head[51][51],tot[51];
void addE(int now,int u,int v){
E[++tot[now]][now].link=head[u][now];
E[tot[now]][now].to=v;
head[u][now]=tot[now];
return;
}
int rt[2],siz[51],dp[51]={998244353};
void getrt(int id,int now,int f){
dp[now]=0;
siz[now]=1;
for(int i=head[now][id];i;i=E[i][id].link){
if(E[i][id].to==f)continue;
getrt(id,E[i][id].to,now);
siz[now]+=siz[E[i][id].to];
dp[now]=max(dp[now],siz[E[i][id].to]);
}
dp[now]=max(dp[now],n[id]-siz[now]);
if(dp[now]==dp[rt[0]])rt[1]=now;
else if(dp[now]<dp[rt[0]])rt[0]=now,rt[1]=0;
return;
}
#define ull unsigned long long
ull hh[51];
ull mask=chrono::steady_clock::now().time_since_epoch().count();
ull S(int x){
x^=mask;
x^=x<<5;
x^=x>>7;
x^=x<<13;
x^=mask;
return x;
}
ull gethash(int id,int now,int f){
int H=1;
for(int i=head[now][id];i;i=E[i][id].link){
if(E[i][id].to==f)continue;
H=(H+S(gethash(id,E[i][id].to,now)));
}
return H;
}
int ans[101];
int main(){
ios::sync_with_stdio(0);
cin>>m;
int temp;
for(int i=1;i<=m;i++){
cin>>n[i];
for(int j=1;j<=n[i];j++){
cin>>temp;
if(temp)addE(i,temp,j),addE(i,j,temp);
}
rt[0]=rt[1]=0;
getrt(i,1,0);
hh[i]=gethash(i,rt[0],0);
if(rt[1])hh[i]=min(hh[i],gethash(i,rt[1],0));
}
for(int i=1;i<=m;i++){
for(int j=1;j<=m;j++){
if(hh[i]==hh[j]){
ans[i]=j;
break;
}
}
}
for(int i=1;i<=m;i++)cout<<ans[i]<<"\n";
return 0;
}
|
经测试,自然溢出的正确率最高。
下班!
虚树
鸽…咕咕咕…
练习题
鸽…咕咕咕…
